Is there really a need to click on settings during a job? I cant think of one time I have ever thought I needed to go in there while a job was running. If I was skipping steps and wanted to up the current, well my job is already trash from the missed steps so I would stop it before going into settings. Just trying to understand why this is such an issue.
I run mine from a cheap fire tablet. That is all I do with that tablet. So its never off of that screen for it to need to refresh. I also run mine in STA so I don’t have connection issues.
I get that some of this “shouldn’t” be happening. But it feels a lot more like a “how you run fluidnc” issue than anything else.
Same here, now I know about some of the quirks. As a new User, the quirks were/will-be frustrating to new Users not aware of the tightrope they need to walk during a cut.
Same, am curious, will try some air cuts, but with serial comms logged. What’s the easiest way to do this, wired USB cable to PC, or some FluidNC log, or something else? e.g. Separate ESP32-S2 or S3 acting as USB host that just logs serial comms.
I don’t have much experience here but I believe the recommended way is to have a wired USB cable to PC with FluidTerm open. When it crashes, you can’t see the crash details from the WebUI but you should be able to from FluidTerm.
Usb cables aren’t an option in my case, all cables fails at some point, also 10+ feet of usb extension is a no go.
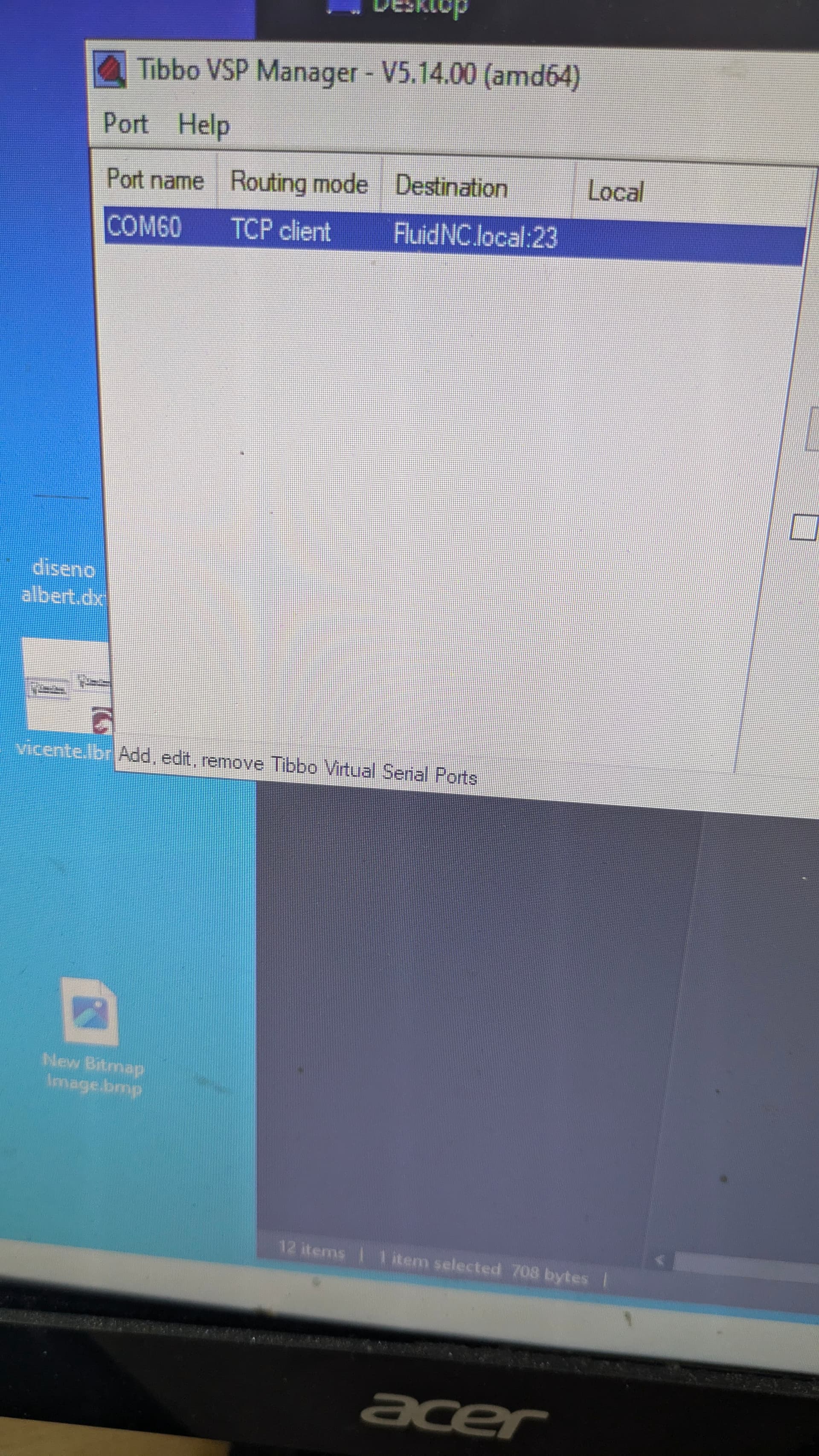
If someone is interested: you can install a virtual com port and just use it like if it is wired _make sure you have a stable wifi between devices*. I use lightburn with one of my machines that way and never had any issues
This makes me wonder if there is a way to cause the settings to load in the background at the start, so they will already be downloaded later if clicked on. ?
But why do you need to use the config/settings page during a job? You cant even save anything without soft reset
I use the tablet mode (v2 ui) on Fullscreen. I only use the main tab for homing the machine and setting Z, then i go to tablet mode and do jobs selection/upload and everything else from there. Never had any issues
As a workaround for Tablet’s users, you can make your screen to be always On if you are using it as a dedicated interface and have a nice wall charger at hand
I can’t think of any “absolutely essential” reasons, but there’s been a time or two I was curious to just double check how much current was going to the steppers. I tend to think most anyone would understand that trying to “save” newly updated values during a cut is a deal breaker, yet likely would not intuitively think that just glancing at the current values during a cut is a deal breaker.
K, makes sense but i never opened the settings page after i dialed things in. I keep a folder with bacups of my config with date and some notes of what was changed. Also have a box with a couple of esp32 fully configured with different fluidnc version but none recent ones. Today upgraded one and got the errors within 20 minutes of use. Will be running the old ver for a while on my machines
Are you thinking something like a Jackpot / FluidNC release status topic with the first post maintained by Ryan/Admins containing a summary of latest recommended version, tips/advice for success. Or should that info be in the JackPot docs? Personally, as a User, I appreciate seeing all these recent posts in such a topic that shows what’s working for people, issues people hit and overcome, and where the current dragons be.
Did you encounter an unexpected error during an active cut job that impacted that cut, even though you wasn’t fiddling with the WebUI?
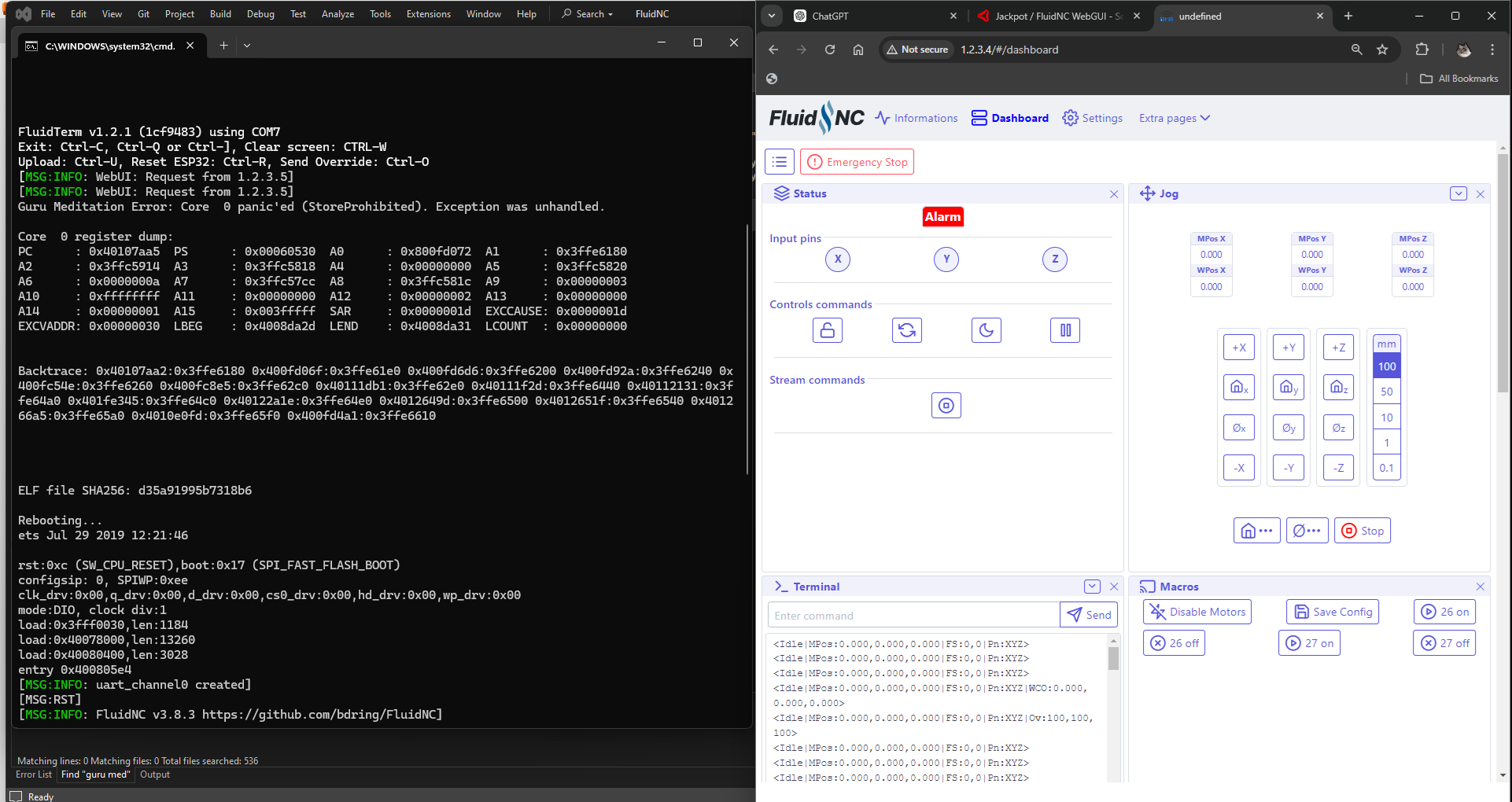
Like that FluidTerm .exe or .py on the client device can wirelessly (via telnet port 23 endpoint on FluidNC ESP32) receive and render fault/backtrace/callstack info:
That’s a nice debugging trick, but does having the telnet server running on FluidNC consume resources that make the crash more likely?
At any rate, was your crash dump from a running job with no other known cause of crash (e.g. just a job you started and let run without reloads or settings changes or whatever?)
Good question, I don’t know. Will keep that possibility in mind.
No. This was me just forcing a crash to understand whether FluidTerm would wirelessly receive fault/callstack info, I didn’t expect that, was a pleasant surprise. Cesar’s screen cap showing Telnet port 23 being used for FluidTerm got me curious. Will try and figure out where .pdb symbols or ESP32/IDF equivalent are to map callstack addresses back to source for a given FluidNC release.
this is concerning as well (this is from discord):
It is not likely to be a problem with the GCode file itself, but rather a latent FluidNC problem that occurs only under a confluence of events. A long GCode run gives enough time for the confluence to happen.
If there are a lot of long, straight lines the gcode is pretty short. Like, Go from 0/0/0 to 100/0/0 is one line. If you have a carving though it has like, hundreds of operation in a few seconds because X/Y/Z all need to move simultaneously in very small increments.
Mabye that’s the difference?
I haven’t done a 3d carve job in ages, thats not my line of work. That said you can trigger the error with simple code exectuting and just open the config window and hit the esp32 file tab. Throws me an error